The PageSpeed modules
(not to be confused with the
PageSpeed Insights
site analysis service),
are open-source webserver modules that optimize your site automatically.
Namely, there is mod_pagespeed
for the Apache server and
ngx_pagespeed
for the Nginx server.
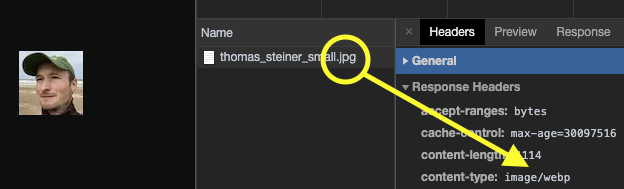
For example, PageSpeed can automatically create WebP versions for all your image resources,
and conditionally only serve the format to clients that accept image/webp.
I use it on this very blog, inspect a request to any JPEG image
and see how on supporting browsers it gets served as WebP.
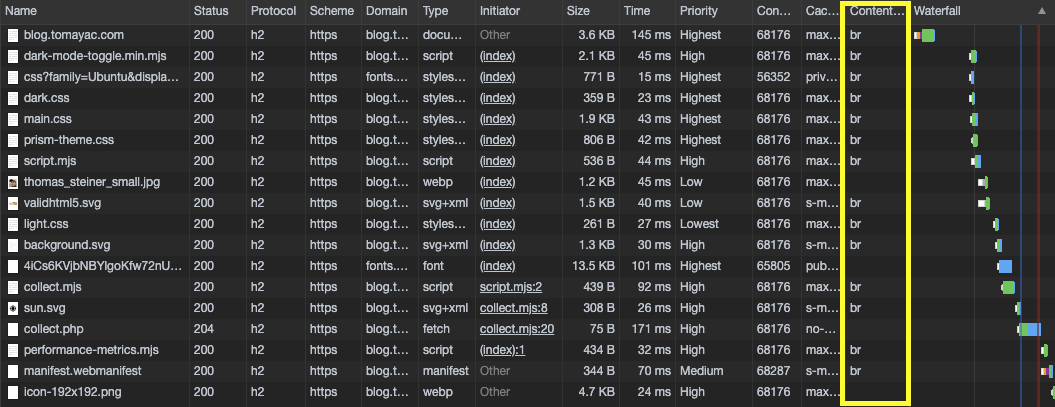
When it comes to compression, Brotli really makes a difference.
Brotli compression is only supported over HTTPS and is requested by clients
by including br in the accept-encoding header.
In practice, Chrome sends
accept-encoding: gzip, deflate, br.
As an example for the positive impact compared to gzip, check out a recent case study shared by
Addy Osmani
in which the web team of the hotel company Treebo share their
Tale of Brotli Compression.
The even better news is that while we are waiting for native Brotli support in PageSpeed,
we can just outsource Brotli compression to the underlying webserver.
To do so, simply disable PageSpeed's HTTPCache Compression.
Quoting from the documentation:
To configure cache compression, set HttpCacheCompressionLevel to values between -1 and 9,
with 0 being off, -1 being gzip's default compression, and 9 being maximum compression.
📢 So to make PageSpeed work with Brotli, what you want in your
pagespeed.conf
file is a new line:
# Disable PageSpeed's gzip compression, so the server's # native Brotli compression kicks in via `mod_brotli` # or `ngx_brotli`. ModPagespeedHttpCacheCompressionLevel 0
Rather than hoping for graceful degradation, [progressive enhancement] builds documents
for the least capable or differently capable devices first,
then moves on to enhance those documents with separate logic for presentation,
in ways that don't place an undue burden on baseline devices
but which allow a richer experience for those users with modern graphical browser software.
While in 2003, progressive enhancement was mostly about using presentational features
like at the time modern CSS properties, unobtrusive JavaScript for improved usability,
and even nowadays basic things like Scalable Vector Graphics;
I see progressive enhancement in 2020 as being about using new functional browser capabilities.
Feature support for core JavaScript language features by major browsers is great.
Kangax' ECMAScript 2016+ compatibility table
is almost all green, and browser vendors generally agree and are quick to implement.
In contrast, there is less agreement on what we colloquially call Fugu 🐡 features.
In Project Fugu,
our objective is the following:
Enable web apps to do anything native apps can,
by exposing the capabilities of native platforms to the web platform,
while maintaining user security, privacy, trust, and other core tenets of the web.
To get an impression of the debate around these features
when it comes to the different browser vendors, I recommend reading the discussions
around the request for a
WebKit position on Web NFC
or the request for a
Mozilla position on screen Wake Lock
(both discussions contain links to the particular specs in question).
In some cases, the result of these positioning threads might be a "we agree to disagree".
And that's fine.
As a result of this disagreement, some Fugu features
will probably never be implemented by all browser vendors.
But what does this mean for developers?
Now and then, in 2003 just like in 2020,
feature detection
plays a central role.
Before using a potentially future new browser capability like, say, the
Native File System API,
developers need to feature-detect the presence of the API.
For the Native File System API, it might look like this:
if('chooseFileSystemEntries'in window){ // Yay, the Native File System API is available! 💾 }else{ // Nay, a legacy approach is required. 😔 }
In the worst case, there is no legacy approach (the else branch in the code snippet above).
Some Fugu features are so groundbreakingly new that there simply is no replacement.
The Contact Picker API (that allows users to select contacts
from their device's native contact manager) is such an example.
But in other cases, like with the Native File System API,
developers can fall back to
<a download>
for saving and
<input type="file">
for opening files.
The experience will not be the same (while you can open a file, you cannot write back to it;
you will always create a new file that will land in your Downloads folder),
but it is the next best thing.
A suboptimal way to deal with this situation would be to force users to load both code paths,
the legacy approach and the new approach.
Luckily,
dynamic import()
makes differential loading feasible and—as a
stage 4 of the TC39 process
feature—has great browser support.
I have been exploring this pattern of progressively enhancing a web application with Fugu features.
The other day, I came across an interesting project by
Christopher Chedeau, who also goes by
@Vjeux on most places on the Internet.
Christopher blogged
about a new app of his, Excalidraw, and how the project "exploded"
(in a positive sense).
Made curious from the blog post, I played with the app myself
and immediately thought that it could profit from the Native File System API.
I opened an initial Pull Request
that was quickly merged and that implements the fallback scenario mentioned above,
but I was not really happy with the code duplication I had introduced.
As the logical next step, I created an experimental library
that supports the differential loading pattern via dynamic import().
Introducing browser-nativefs,
an abstraction layer that exposes two functions, fileOpen() and fileSave(),
which under the hood either use the Native File System API or the <a download> and
<input type="file"> legacy approach.
A Pull Request based on this library is now merged
into Excalidraw, and so far it seems to work fine (only the dynamic import()breaks CodeSandbox,
likely a known issue).
You can see the core API of the library below.
// The imported methods will use the Native File // System API or a fallback implementation. import{ fileOpen, fileSave, }from'https://unpkg.com/browser-nativefs';
(async()=>{ // Open a file. const blob =awaitfileOpen({ mimeTypes:['image/*'], });
// Open multiple files. const blobs =awaitfileOpen({ mimeTypes:['image/*'], multiple:true, });
// Save a file. awaitfileSave(blob,{ fileName:'Untitled.png', }); })();
#148
on whether a File object should have an attribute
that points to its associated
FileSystemHandle.
#149
on the ability to provide a name hint for a to-be-saved file.
There are several other open issues
for the API, and its shape is not stable yet.
Some of the API's concepts like FileSystemHandle only make sense when used with the actual API,
but not with a legacy fallback,
so polyfilling
or ponyfilling (as pointed out by my colleague
Jeff Posnick) is—in my humble opinion—less of an option,
at least for the moment.
My current thinking goes more in the direction of positioning this library as an abstraction
like jQuery's $.ajax() or
Axios' axios.get(),
which a significant amount of developers still prefer even over newer APIs like fetch().
In a similar vein, Node.js offers a function
fsPromises.readFile()
that—apart from a FileHandle—also
just takes a filename path string, that is, it acts as an optional shortcut to
fsPromises.open(),
which returns a FileHandle
that one can then use with
filehandle.readFile()
that finally returns a Buffer or a string, just like fsPromises.readFile().
Thus, should the Native File System API then just have a window.readFile() method? Maybe.
But more recently the trend seems to be to rather expose generic tools like
AbortController
that can be used to cancel many things, including
fetch()
rather than more specific mechanisms.
When the lower-level primitives are there, developers can build abstractions on top,
and optionally never expose the primitives, just like the fileOpen() and fileSave() methods
in browser-nativefs that one can (but never has to) perfectly use
without ever touching a FileSystemHandle.
Progressive enhancement in the age of Fugu APIs in my opinion is more alive than ever.
I have shown the concept at the example of the Native File System API,
but there are several other new API proposals where this idea (which by no means I claim as new)
could be applied.
For instance, the Shape Detection API
can fall back to JavaScript or Web Assembly libraries, as shown in the
Perception Toolkit.
Another example is the (screen) Wake Lock API
that can fall back to playing an invisible video,
which is the way NoSleep.js implements it.
As I wrote above, the experience probably will not be the same,
but the next best thing.
If you want, give browser-nativefs a try.
I was curious to see if they did something special when they detect a page is using AMP
(spoiler alert: they do not),
so I quickly hacked together a fake AMP page that seemingly fulfilled their simple test.
<html⚡️> <body>Fake AMP</body> </html>
I am a big emoji fan, so instead of the
<html amp>
variant, I went for the <html ⚡> variant and entered the ⚡ via the macOS emoji picker.
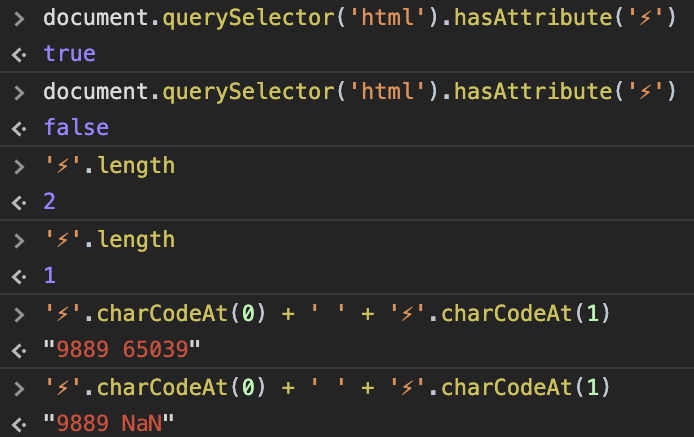
To my surprise, Facebook logged "FBNavAmpDetect: false". Huh 🤷♂️?
My first reaction was: <html ⚡️> does not quite look like what the founders of HTML had in mind,
so maybe hasAttribute()
is specified to return false
when an attribute name is invalid.
But what even is a valid attribute name?
I consulted the HTML spec
where it says (emphasis mine):
Attribute names must consist of one or more characters
other than controls, U+0020 SPACE, U+0022 ("), U+0027 ('), U+003E (>), U+002F (/), U+003D (=),
and noncharacters. In the HTML syntax, attribute names, even those for foreign elements,
may be written with any mix of ASCII lower and ASCII upper alphas.
I was on company chat with Jake Archibald at that moment,
so I confirmed my reading of the spec that ⚡ is not a valid attribute name.
Turns out, it is a valid name, but the spec is formulated in an ambiguous way, so Jake filed
"HTML syntax" attribute names.
And my lead to a rational explanation was gone.
Luckily a valid AMP boilerplate example
was just a quick Web search away, so I copy-pasted the code and Facebook, as expected,
reported "FBNavAmpDetect: true".
I reduced the AMP boilerplate example until it looked like my fake AMP page,
but still Facebook detected the modified boilerplate as AMP, but did not detect mine as AMP.
Essentially my experiment looked like the below code sample.
Perfect Heisenbug?
An invisible code point which specifies that the preceding character should be displayed
with emoji presentation. Only required if the preceding character defaults to text presentation.
You may have seen this in effect with the Unicode snowman that appears in a textual ☃︎
as well as in an emoji representation ☃️ (depending on the device you read this on,
they may both look the same).
As far as I can tell, Chrome DevTools prefers to always render the textual variant,
as you can see in the screenshot above.
But with the help of the
length()
and the
charCodeAt()
functions, the difference gets visible.
The macOS emoji picker creates the variant ⚡️, which includes the Variation Selector-16,
but AMP requires the variant without, which I have also confirmed in the
validator code.
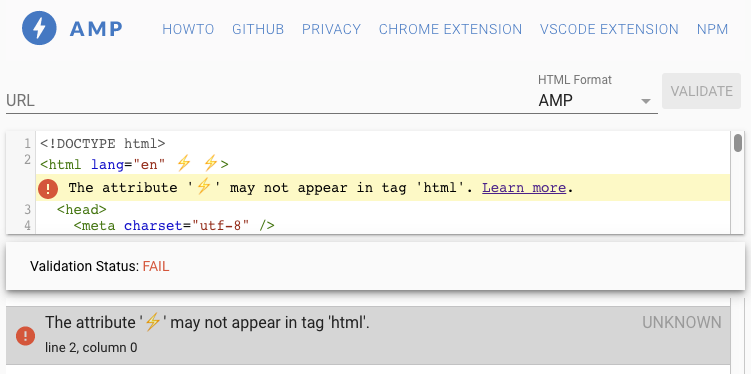
You can see in the screenshot below how the AMP Validator
rejects one of the two High Voltage symbols.
I have filed crbug.com/1033453 against the Chrome DevTools
asking for rendering the characters differently, depending on whether the Variation Selector-16
is present or not.
Further, I have opened a feature request on the AMP Project repo demanding that
AMP should respect ⚡️ apart from ⚡.
Same same, but different.
Both
Facebook's Android app
as well as
Facebook's iOS app use a so-called in-app browser,
sometimes also referred to as IAB.
The core argument for using an in-app browser (instead of the user's default browser)
is to keep users in the app and to enable closer app integration patterns
(like "quote from a page in a new Facebook post"), while making others harder or even impossible
(like "share this link to Twitter").
Technically, IABs are implemented as
WebViews on Android,
respectively as
WKWebViews on iOS.
To simplify things, from hereon, I will refer to both simply as WebViews.
In-App Browsers are less capable than real browsers ⚓
Turns out, WebViews are rather limited compared to real browsers like Firefox, Edge, Chrome,
and to some extent also Safari.
In the past, I have done some research
on their limitations when it comes to features that are important in the context of Progressive Web Apps.
The linked paper has all the details, but you can simply see for yourself by opening
the 🕵️ PWA Feature Detector app
that I have developed for this research in your regular browser,
and then in a WebView like Facebook's in-app browser (you can share the
link visible to just yourself on Facebook
and then click through, or try to open my
post in the app).
On top of limited features, WebViews can also be used for effectively conducting intended
man-in-the-middle attacks,
since the IAB developer can arbitrarily
inject JavaScript code
and also
intercept network traffic.
Most of the time, this feature is used for good.
For example, an airline company might reuse the 💺 airplane seat selector logic
on both their native app as well as on their Web app.
In their native app, they would remove things like the header and the footer,
which they then would show on the Web (this is likely the origin of the
CSS can kill you meme).
For these reasons, people like Alex Russell—whom
you should definitely follow—have been advocating against WebView-based IABs.
Instead, you should wherever possible use
Chrome Custom Tabs on Android,
or the iOS counterpart
SFSafariViewController.
Alex writes:
Note that responsible native apps have a way of creating an "in app browser" that doesn't subvert user choice or break the web:
The other day, I learned with great joy that Facebook finally have marked their IAB debuggable 🎉.
Patrick Meenan—whom you should likewise follow
and whom you might know from the amazing WebPageTest
project—writes in a Twitter thread:
You can now remote-debug sites in the Facebook in-app browser on Android.
It is enabled automatically so once your device is in dev mode with USB debugging
and a browser open just visit chrome://inspect to attach to the WebView.
The browser (on iOS and Android) is just a WebView so it should behave
mostly like Chrome and Safari but it adds some identifiers to the UA string
which sometimes causes pages that UA sniff to break.
Finally, if your analytics aren't breaking out the in-app browsers for you,
I highly recommend you see if it is possible to enable.
You might be shocked at how much of your traffic comes from an in-app browser
(odds are it is the 3rd most common browser behind Chrome and Safari).
I have thus followed up on the invitation and had a closer look at their IAB by inspecting
example.org and also a simple test page
facebook-debug.glitch.me that contains the
debugger
statement in its head.
I have linked a debug trace 📄 that you can open for yourself
in the Performance tab of the Chrome DevTools.
As pre-announced by Patrick, Facebook's IAB changes the user-agent string.
The
default WebView user-agent string
looks something like Mozilla/5.0 (Linux; Android 5.1.1; Nexus 5 Build/LMY48B; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/43.0.2357.65 Mobile Safari/537.36
Facebook's IAB browser currently sends this:
navigator.userAgent // "Mozilla/5.0 (Linux; Android 10; Pixel 3a Build/QQ2A.191125.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.108 Mobile Safari/537.36 [FB_IAB/FB4A;FBAV/250.0.0.14.241;]"
Compared to the default user-agent string, the identifying bit is the suffix [FB_IAB/FB4A;FBAV/250.0.0.14.241;].
Facebook runs some performance monitoring via the
Performance interface.
This is split up in two scripts, each of which they seem to run three times.
They also check if a given page is using AMP
by checking for the presence of the amp or ⚡️ attribute on <html>.
They run some Feature Policy
tests via a function named getFeaturePolicyAllowListOnPage().
You can see the documentation for the tested
directives
on the Mozilla Developer Network.
Not all directives are currently supported by the WebView, so a number of warnings are logged.
The recognized ones (i.e., the output of the getFeaturePolicyAllowListOnPage() function above)
result in an object as follows.
I checked the response and request headers, but nothing special stood out.
The only remarkable thing given that they look at Feature Policy is the absence of the
Feature-Policy header.
All in all, these are all the things Facebook did that I could observe
on the pages that I have tested.
I didn't notice any click listeners or scroll listeners
(that could be used for engagement tracking of Facebook users with the pages they browse on)
or any other kind of "phoning home" functionality,
but they could of course have implemented this natively
via the WebView's
View.OnScrollChangeListener
or
View.OnClickListener,
as they
did
for long clicks for the FbQuoteShareJSInterface.
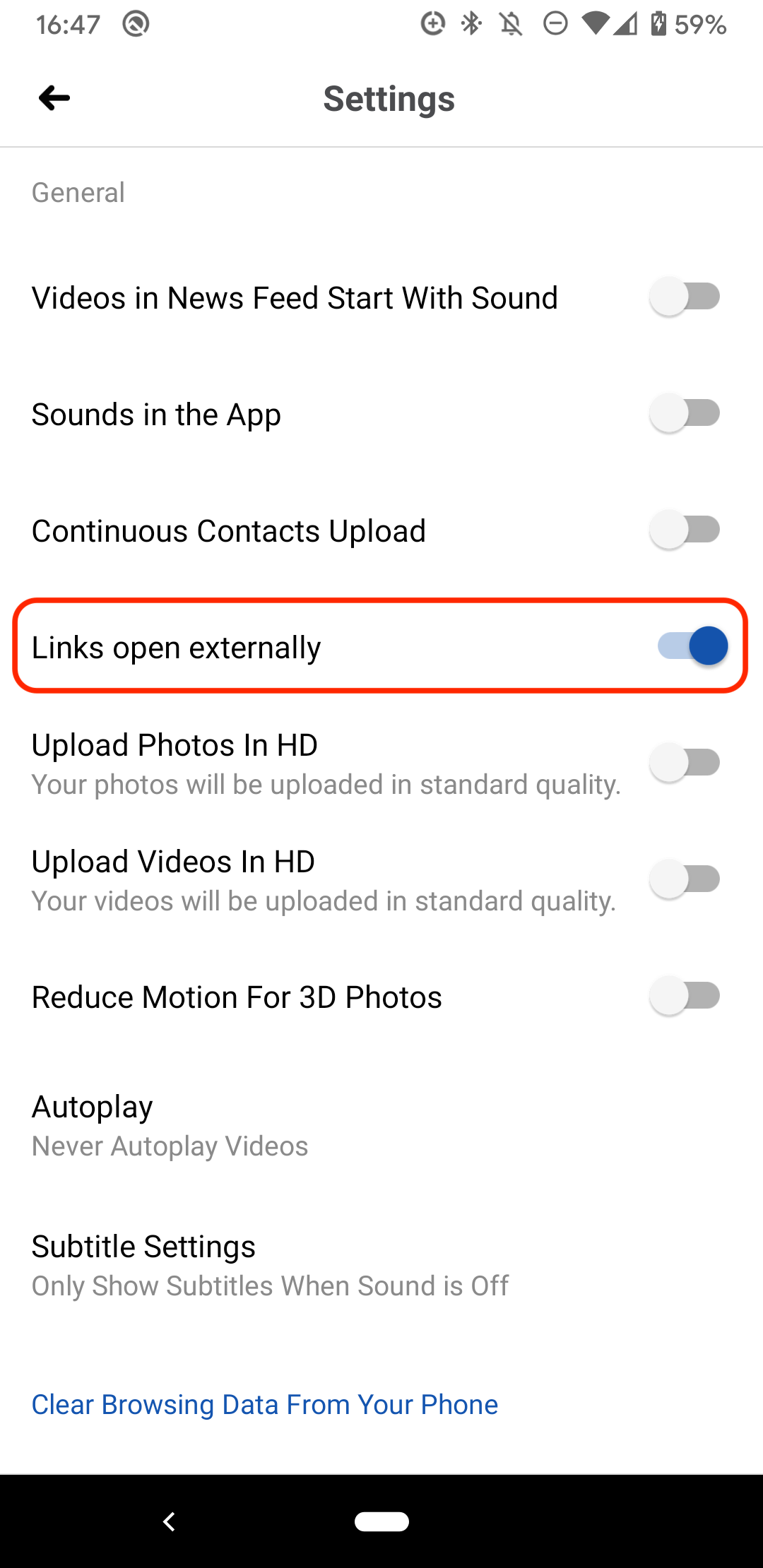
That being said, if after reading this you prefer your links to open in your default browser,
it's well hidden, but definitely possible: Settings > Media and Contacts > Links open externally.
It goes without saying, but just in case:
all code snippets in this post are owned by and copyright of Facebook.
Did you run a similar analysis with similar (or maybe different) findings?
Let me know on Twitter or Mastodon by posting your thoughts with a link to this post.
It will then show up as a Webmention at the bottom.
On supporting platforms, you can simply use the "Share Article" button below.
When it comes to animating SVGs, there're three options: using
CSS,
JS, or
SMIL.
Each comes with its own pros and cons, whose discussion is beyond the scope of this article,
but Sara Soueidan has a great
article on the topic.
In this post, I add a repeating shrink animation to a circle with all three methods,
and then try to use these SVGs as favicons.
Here's an example of animating an SVG with CSS based on the
animation and the
transform properties.
I scale the circle from the center and repeat the animation forever:
The SVG <script>
tag allows to add scripts to an SVG document.
It has some subtle differences
to the regular HTML <script>, for example, it uses the href instead of the src attribute,
but above all it's important to know that any functions defined within any <script> tag
have a global scope across the entire current document.
Below, you can see an SVG script used to reduce the radius of the circle until it's equal to zero,
then reset it to the initial value, and finally repeat this forever.
<svgviewBox="0 0 100 100"xmlns="http://www.w3.org/2000/svg"> <circlefill="blue"cx="50"cy="50"r="45"/> <scripttype="text/javascript"><![CDATA[ const circle = document.querySelector('circle'); let r =45; constanimate=()=>{ circle.setAttribute('r', r--); if(r ===0){ r =45; } requestAnimationFrame(animate); }; requestAnimationFrame(animate); ]]></script> </svg>
The last example uses SMIL, where, via the
<animate>
tag inside of the <circle> tag, I declaratively describe that I want to
animate the circle's r attribute (that determines the radius) and repeat it indefinitely.
Before using animated SVGs as favicons, I want to briefly discuss
how you can use each of the three examples on a website.
Again there're three options: referenced via the src attribute of an <img> tag,
in an <iframe>, or inlined in the main document.
Again, SVG scripts have access to the global scope, so they should definitely be used with care.
Some user agents, for example, Google Chrome, don't run scripts for SVGs in <img>.
The Glitch embedded below shows all variants in action.
My recommendation would be to stick with CSS animations whenever you can,
since it's the most compatible and future-proof variant.
Since crbug.com/294179 is fixed, Chrome finally supports SVG favicons,
alongside many other browsers.
I have recently successfully experimented with
prefers-color-scheme in SVG favicons,
so I wanted to see if animated SVGs work, too.
Long story short, it seems only Firefox supports them at the time of writing,
and only favicons that are animated with either CSS or JS.
You can see this working in Firefox in the screencast embedded below.
If you open my Glitch demo in a standalone window,
you can test this yourself with the radio buttons at the top.
Should you use this in practice?
Probably not, since it can be really distracting.
It might be useful as a progressive enhancement to show activity during a short period of time,
for example, while a web application is busy with processing data.
Before considering to use this, I would definitely recommend taking the user's
prefers-reduced-motion
preferences into account.
I started to blog way back in 2005,
and while I was skeptical whether it would work out and was worth my time,
I just tried it and danced 💃 and wrote like no one was watching
(which definitely was the case for a while).
Many of these early posts are slightly embarrassing from today's point of view,
but nevertheless I decided to keep them around, since they are a part of me.
Remember, this was before social networks became a thing.
Actually, social networks almost killed my blogging, in both
2016
and 2017
respectively I only wrote one post, but plenty of tweets
and Facebook posts.
Here's a screenshot of the
old blog:
One of the reasons why I blogged less was also my hand-rolled stack that the blog was built upon:
A classic LAMP stack, consisting of Linux, Apache, MySQL, and handwritten PHP 5.
Since I had (and still have) no clue of MySQL character encoding configuration,
I couldn't store emoji 🤔 in my database, but hey ¯\_(ツ)_/¯.
The switch to HTTPS then killed my login system (that before on HTTP anyone could have sniffed,
did I mention I was clueless?).
In the end I had to log into phpMyAdmin to enter a new blog post into the database by hand.
It was clearly time for a change.
Luckily this was the time when static site builders became more and more popular.
I had heard good things of Zach Leatherman's
Eleventy, so I went for it.
It was super helpful to have the
eleventy-base-blog
repository that shows how to get started with Eleventy.
I took extra care to make sure all my old URLs still worked,
and learned more than I wanted about
.htaccess files
and .htaccess rewrite maps,
since we all know that cool URIs don't change.
There I was with a modern stack, and a 2005 design.
Now, I've finally also updated the design, and, while I'm not a designer, I still quite like it.
Obviously it supports
prefers-color-scheme, aka. Dark Mode
and also uses the <dark-mode-toggle>
custom element, but I've also decided to go for a responsive "holy grail" layout
that is based on CSS Grid.
Here're the resources that helped me build the new Blogccasion:
The core of my CSS Grid code is from Alligator's article
CSS Grid: Holy Grail Layout.
I learned about the particularities of Grid's minimum size of an fr unit, which is auto
and which caused a Grid blowout described in Chris Coyier's
aptly named article
Preventing a Grid Blowout.
The Synthwave '84 code theme for Visual Studio Code originally is from Robb Owen.
I'm using the port for PrismJS by Marc Backes.
🙏 Thanks everyone for letting me stand on your shoulders!
There're still some rough edges, so if you encounter a problem, please report an
issue.
It's well-known that there're a lot of encoding errors in the older posts.
At some point I broke my database in an attempt to convert it to UTF-8 🤦♂️…
If you care, you can also propose an edit straightaway,
the edit this page on GitHub link is 👇 at the bottom of each post.
Thanks, and welcome to the new Blogccasion.
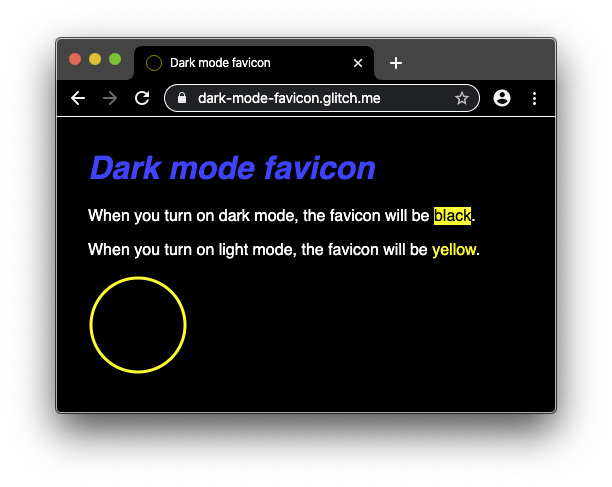
🎉 Chrome finally accepts SVG favicons now that crbug.com/294179,
where this feature was demanded on September 18, 2013(!), was fixed.
This means that you can style your icon with inline prefers-color-scheme
and you'll get two icons for the price of one!
You can see a demo of this in action at 🌒 dark-mode-favicon.glitch.me ☀️.
Until this feature will have landed in Chrome Stable/Beta/Dev/Canary, be sure to test it with the last Chromium build
that you can download from François Beaufort's Chromium Downloader.
Full credits to Mathias Bynens,
who independently
has created almost the same demo as me that I didn't check,
but whose link to Jake Archibald's post
SVG & media queries I did follow.
Mathias has now filed the follow-up bug crbug.com/1026539
that will improve the favicon update behavior (now you still need to reload the page after a color scheme change).
This week, I attended my now third W3C
TPAC.
After TPAC 2017
in Burlingame, CA, United States of America and
TPAC 2018 in Lyon, France,
TPAC 2019 was held in Fukuoka, Japan.
For the first time, I felt like I could somewhat meaningfully contribute and
had at least a baseline understanding of the underlying W3C mechanics.
As each year, the TPAC agenda was crammed
and overlaps were unavoidable.
Below is the write-up of the meetings I had time to attend.
On Monday, I attended the Service Workers Working Group
(WG) meeting.
The agenda this time
was a mix of implementor updates, new proposals, and a lot of discussion of special cases.
I know Jake Archibald is working on a summary post,
so I leave it to him to summarize the day.
The
raw meeting minutes
are available in case you're interested.
On Tuesday, I visited the
Web Application Security Working Group
meeting as an observer.
I was mostly interested in this WG because the
agenda
promised interesting proposals like Apple's
/.well-known/change-password
that was met with universal agreement.
Some interesting discussion also sparked around again Apple's
isLoggedIn()
API proposal.
I was reminded of why on the web we can't have nice things through an attack vector
that leverages HSTS for tracking purposes.
Luckily there is
browser mitigation
in place to prevent this.
The
meeting minutes
cover the entire day.
Wednesday was unconference day with
59(!) breakout sessions.
Other than the at times tedious working group sessions,
I find breakout sessions to be oftentimes more interesting and an opportunity to learn new things.
The first breakout session I attended was on
JS built-in modules,
a TC39 proposal by Apple for a
JavaScript Built-in Library.
The session's minutes are available,
in general there was a lot of discussion and disagreement around namespaces and
how built-in modules should be governed.
Breakout Session New Module Types: JSON, CSS, and HTML ⚓
The next session was on
new module types for JSON, CSS, and HTML.
As the developer of
<dark-mode-toggle>,
I'm fully in favor of getting rid of the clumsy
innerHTML all the things!!!1!
approach that vanilla JS custom elements currently make the programmer to follow.
If you're likewise interested, subscribe to the
CSS Modules issue and the
HTML Modules issue
in the Web Components WG repo.
The discussion circulated mostly around details how @imports would work and
how to convey the type of the import to avoid security issues,
for example following the <link rel="preload"> way.
The meeting minutes
have the full details.
The Mini App Standardization
session, organized by the Chinese Web Interest Group,
was super interesting to me.
In preparation of the
Google Developer Days in Shanghai, China,
that I spoke at right before TPAC, I have
looked at WeChat mini programs
and documented the developer experience and how close to and yet how far from the web they are.
A couple of days before TPAC, the Chinese Web Interest Group had released a
white paper that documents their ideas.
The success the various mini apps platforms have achieved deserves our full respect.
There were, however, various voices—including from the
TAG—that urged the various stakeholders
to converge their work with efforts made in the area of
Progressive Web Apps, for example around the Web App Manifest
rather than create yet another manifest-like format.
Read the full session minutes for all details.
One of the results of the session was the creation of the
MiniApps Ecosystem Community Group
that I hope to join.
Breakout Session For a More Capable Web—Project Fugu ⚓
Together with Anssi Kostiainen from Intel and
John Jansen from Microsoft,
I organized a breakout session
for a more capable web
under the umbrella of Project Fugu 🐡.
You can see our slides embedded below.
In the session we argue that to remain relevant with native, hybrid, or mini apps, web apps, too,
need access to a comparable set of APIs.
We briefly touched upon the APIs being worked on by the cross-company project partners,
and then opened the floor for an open discussion on why we see the browser-accessible web in danger
if we don't move it forward now,
despite all fully acknowledged challenges around privacy, security, and compatibility.
You can follow the discussion in the excellent(!)
session minutes, courtesy of Anssi.
Thursday and Friday were dedicated to the Devices and Sensor WG.
The agenda was not too packed,
but still kept us busy for one and a half days.
We discussed almost from the start about permissions and how they should be handled.
Permissions are a big topic in Project Fugu 🐡 and I'm happy
that there's work ongoing in the TAG to improve the situation, including efforts around the
Permissions API
that is unfortunately not universally supported, leading to inconsistencies
with some APIs having a static method for getting permission,
others
asking for permission upon the first usage attempt,
and yet others to integrate with the Permissions API.
For the Geolocation Sensor API,
we agreed to try retrofitting expressive configuration
of foreground tracking into the Geolocation API
specification instead of doing it in Geolocation Sensor, which should improve vendor adoption.
For geofencing and background geolocation tracking, we decided to explore
Notification Triggers and
Wake Locks respectively,
which both weren't options when the work on Geolocation Sensor was started initially.
Maryam Mehrnezhad,
an invited expert in the working group whose research is focused on privacy and security,
presented on and discussed with us the implications on both fields that sensors potentially have
and whether mitigation like accuracy bucketing or frequency capping are effective.
The minutes capture the conversation well.
Finally, we
changed the surface of the Wake Lock API
hopefully for the last time.
The previous changes just didn't feel right from a developer experience point of view,
so better change the API while it's behind a flag than be sorry forever.
I reckon I do feel sorry for the implementors Rijubrata Bhaumik
and Raphael Kubo da Costa… 🙇
[Exposed=(Window,DedicatedWorker)] interfaceWakeLock{ Promise<unsigned long long>request(WakeLockType type); Promise<void>release(unsigned long long wakeLockID); };
dictionary WakeLockEventInit { required unsigned long long wakeLockID; };
[Exposed=(Window,DedicatedWorker)] interfaceWakeLockEvent: Event { constructor(DOMString type, WakeLockEventInit init); readonly attribute unsigned long long wakeLockID; };
As a general theme, we "hardened" a number of APIs, for example decided to integrate geolocation
with Feature Policy
and now require a secure connection for the Battery Status API.
The chairs Anssi and Reilly Grant
have scribed the one and a half days brilliantly,
the minutes for day 1 and
day 2 are both online.
As I wrote in the beginning, TPAC slowly starts to feel like a venue
where I can make some valuable contributions.
Rowan Merewood put it like this in a
tweet:
The biggest thing I'm learning at
[#W3Ctpac]
is if you want to change the web,
it's a surprisingly small group of people you need to convince.
The surrounding appearance of the W3C and all its language is intimidating,
but underneath it's just other human beings you can talk to.
[Y]eah, but let's not forget getting to talk to that small set of people
most often comes with being very, very, very privileged. […]
It's indeed a massive privilege to work for a company that has the money
to take part in W3C activities, fly people across the world, and let them
stay in five star conference hotels.
With all the love for the web and all the great memories of a fantastic TPAC,
let's not forget: the web is threatened from multiple angles,
and being able to work in the standards bodies on defending it is a privilege of the few.
Both shouldn't be the case.



{kind=link}